


Tools calls are alls that matter
Why is Anthropic still being used the most for agents?


He who controls the spice controls the universe - From Frank Herbert’s Dune
In the AI Agent world, the “spice” happens to be a very particular feature with LLMs, which is commonly known as a tool call or function call. No matter how many math and programming competitions these latest LLMs have beat, one thing that Anthropic seems to still hold the line on the competition is its ability to call tools. After all, if you had a genius group of friends but they didn’t know how to use a wrench, would you still call them to fix your sink or toilet? Probably not. As with these powerful LLM models, some may not know how to achieve a task that is not related to just spitting out text.
But wait, how is Anthropic still on top? LLM Arena doesn’t even have them in the top 10:

The latest model (as of writing) is Grok 3 and they don’t even include it in their benchmarks:

Basically it’s almost as if Anthropic is forgotten, but even with the latest round of reasoning models, which add inference time to think about how to solve a problem, the ability to execute tasks even from a well thought out plan has been a challenge for best frontier models.
Let’s maybe take a step back, first you may be asking, what is a tool call?
It’s simply a way to define and execute an action that is not related to the model data itself. For example, if I asked something like, “What’s the news today?”. The model doesn’t have this baked into the LLM, it needs to reach out to something. There could be a tool call with “web search” that could insert “news today” and return the results for the LLM to then serve back to you. There’s a lot of other examples, for example a common one is using a “code execution” tool to execute even simple math calculations. For example, “what’s 5*20*101*50?” With how LLMs work, it may be easier to actually write code for this rather than rely on the probability of the next word generated, so it would look something like:
# Compute the product of the given numbers
result = 5 * 20 * 101 * 50
result (runs python script in the background)…
Which would spit out 505,000
Thus, there are two tools we have already mentioned, web search and code execution, this could be stored in the LLM like this:
{
"tools": [
{
"name": "web_search",
"description": "Fetches real-time data from the web",
"parameters": {
"query": "string"
}
},
{
"name": "code_execution",
"description": "Executes Python code for calculations",
"parameters": {
"code": "string"
}
}
]
}
Then, when the appropriate tool is identified, it needs to know what to input:
{
"tool": "web.search",
"query": "news today"
}
{
"tool": "python",
"code": "5 * 20 * 101 * 50"
}
Another example is when you use an agentic IDE like Windsurf, if I tell it to make a snake game, it gives me this output:
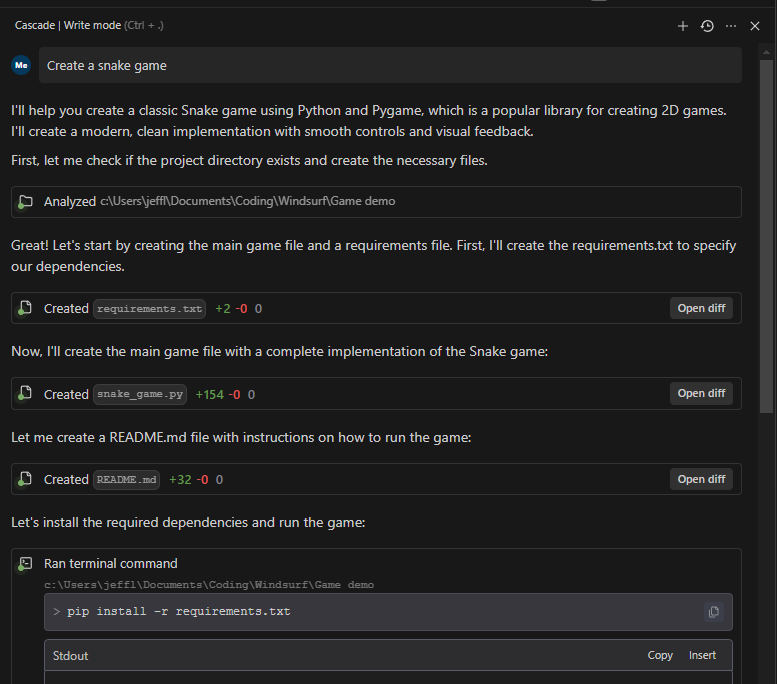
As you can see above, it figured out what languages to use, then analyzed the existing (but empty) folder, then created the requirements to pull dependencies, created the app in python, created the documentation, then ran a terminal command to pull in the right libraries. All these required a tool, input, and response which then could be carried to the next task. All that within seconds, but you can see, each step required a method to execute or write code.
Now there’s one very tricky thing here, how the heck does a model know what to accurately choose if there are an abundance of possible tasks and actions out there? In fact, a model trained on text is not very useful if it doesn’t know what is available to reach out to and get help with. In the above examples, part of it is having the app help define and choose the right tools, but the other part is that the model needs to be trained with the ability to recognize when to use the right tools. Even with the previous 2 examples of web search and python, that could probably get triggered by so many types of chat prompts already, how would a model be able to sift through all that noise?
So being able to choose the right tool is a difficult and important problem that has somehow been solved the best by Anthropic (as of writing), why is this never included in benchmarks? This is really the most important in the context of running multiple tasks and knowing how to do them, or in 2025 buzz word terms, agents. What does an agent do? Well it goes and figures out a plan and carries out tasks!
There’s a major issue here though, even if a frontier model was trained on the entire corpus of available data, there really isn’t a good dataset that points to how to utilize tools that are available in different systems. That’s where Anthropic’s model has a major head start.
Anthropic realized earlier than others that the future of LLMs was the ability to recognize tools and be able to call them based on the inputs. They likely had a year head start to begin fine tuning these models with examples of when to use specific tools and what format to execute them. This is far more challenging than just training on text, it requires very careful curation of taking data that will execute each of these tasks. Instead of taking data and having the probability of the next word coming out you’ll actually have to:
Define available tools and how to execute them
Map prompts to what triggers these tools
Guide the model to these tools correctly
Keep re-training or reinforcing when to correctly use these tools
That seems simple enough right? But wait, there is more…in agents remember you actually need multiple tasks to accomplish your objective. That means that you’ll have to call multiple tools in many cases. The model actually needs to be a good planner as well, or have the ability to bundle multiple tools together to accomplish the prompt. It has to map out multiple tasks, then execute one by one. Think about what has to happen here:
The model needs to identify that a tool is needed for the response
It picks the right tool to use
It formats the inputs (the query in the above section) correctly with only a small prompt
It gives back an appropriate response from the tool call, or hands it off to the next task correctly
There simply isn’t that much data in the real world to do this for every possibility.
But that’s not all either, what if one task doesn’t output correctly and leads the model astray? The model will actually have to reposition itself or replan itself to get back on track. This is where the app layer can be super important to guide the agent back.
For some reason, Anthropic still appears to be the best tool calling LLM and its model is back from October, which is an eternity in AI. Since then, Google has released a new Gemini 2.0 model, OpenAI has released a new o3 model, DeepSeek released R1, Meta is still waiting for its next release, and xAI has released Grok 3. Despite having much more time to beat the previous models, Anthropic is still the most used model for platforms like Windsurf, where it can plan out how to code from a prompt with multi-step changes and suggestions. When you start comparing a single shot prompt that has a very difficult question to answer, this could be where the other models mentioned would outperform (and what most benchmarks are looking at).

In the next few months, the next battle won’t be who has the biggest GPU cluster or who has the largest parameter model, it’ll be who can figure out how to solve a problem that can take multiple steps and execute on the tasks accordingly. Only then will the cost of agents go down and be more widespread. Expect major progress here rapidly, as this will be extremely important to get agents right.