
The AI Trilemma
What makes one LLM better than another?


I originally started this newsletter to force myself to learn more about AI to help get a job in the space. Well, I am proud to announce I am now at Codeium, the free AI platform for Devs, in an assortment of roles as the company navigates this AI Tsunami. As you can imagine, things are moving quickly! Okay, let’s get to the article…
Ever since April of this year (that’s less than 2 months ago), there has been an exponential rate of improvement on Large Language Models (LLMs) and how effective they can actually be. Back then, I wrote an article about the Open Source progress catching up, and coincidentally just a few weeks ago a leaked document from Google, showed a similar thesis. There is an exceptionally quick rate at which open sourced models are approaching GPT4, and that there is a possibility that open sourced models could actually catch up.
How does this work? Well, there are actually multiple ways to improve the effectiveness of AI. It is something we think about very hard at Codeium to stay ahead of the curve. To help illustrate 3 major ways to bolster AI effectiveness, as well as simplifying the conversation, I give you the AI Trilemma. It’s probably less dramatic than that name, but hey if you’re still reading it’s working!
Companies can deploy vast resources to improve either the base model, context, or fine tuning:
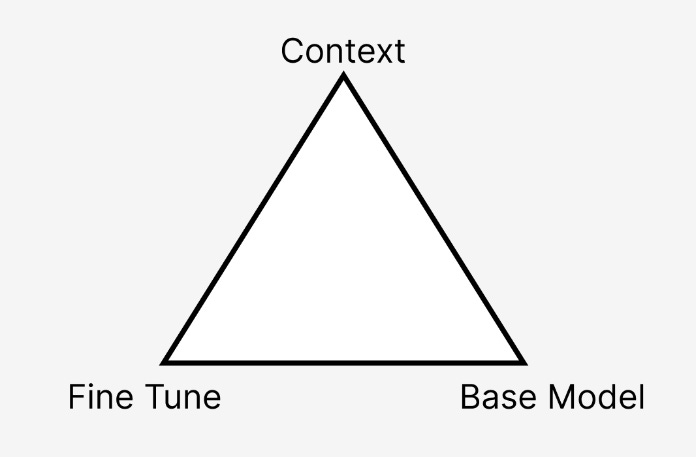
Each of these have trade offs, while the Performance can be improved, the cost to run or maintain these can dwindle the more you throw resources at it. Thus, we can categorize these tradeoffs in the following ways:
Cost to build, or the amount of raw power or money it would take to build the outcome.
Cost to run, or how much money it causes to generate a query the larger it becomes.
Effectiveness, or the ability to improve the model based on throwing more and more resources at it.
Scaling factor, or how easy this could be tweaked for larger and larger organizations.
Base Model
The biggest cost to start is to build the Base Model, since that is simply the most foundational piece of any language model. This is the size of the dataset and quality of the training data that has been aggregated into the LLM. When you go to ChatGPT and select GPT3 or GPT4, there is a major difference in the size of the base model and the cost to run the model. It’s speculated that the size of the model for ChatGPT went from 175B Parameters to 100T in GPT4. However, much of this also depends on the quality of the original dataset. It is interesting that to improve the performance of any LLM, having a much larger dataset helps immensely, but could also increase the cost to run a query. In some cases, it might be even more effective to just throw more data at the problem than to spend time picking out which data to push in.
This is also where OpenAI has a major advantage. The cost to assemble and train GPT4 will likely be very hard to catch up to, even at the pace that the open source community is moving. However, that doesn’t mean that GPT4 is required to fulfill the purpose that people are trying to get from the model. For example if I only want to know Medical Data, Googe’s new Med-PaLM 2 might outperform GPT4 due to its fine tuning (we’ll get to that later).
Right now, many open source base models are being released nearly everyday, each with their specialized outcomes. It is worth noting though that some are stronger at some use cases than others, and just having a large dataset doesn’t mean it is better at some specific things than others. For example Meta’s LLaMa is actually not great at code completion, because only 5% of the dataset was trained on code.
You’ll also notice that both Google and Meta released multiple versions of their base model, each related to the size of hardware that is able to run it. For Google’s lowest PaLM 2 model, Gecko, they claim that it can even be run on a smartphone! However, the performance of the smaller models don’t match their larger brethren at all. Just creating multiple models is also very expensive. Each time a new base model is trained, it can cost thousands, if not hundreds of thousands of dollars to generate. It would not be likely that an organization would generate these frequently, especially if they are created specifically for different use cases. Some organizations are taking advantage of this fact. Stability has been training many base models for many different institutions plainly because others wouldn’t have the capability to generate these themselves.
If you were an organization that wanted to build its own base models, you’d likely have a major dilemma on hand, how many resources would you want to train the base model, and how often would you update it? Also, the size of the model will also dictate the kind of infrastructure you will need to support it. It’s a decision that every organization coming into the AI space has to grapple with.
Therefore for rating this method:
Cost to build: Very High
Cost to run: High
Effectiveness: High
Scaling factor: Low (Would not expect an organization to train many base models)
However it must be noted that if an entire Organization decides to use a massive model, and wants to improve it by building a newer base model, the costs could become extremely prohibitive, so thus we need to explore other ways to improve the effectiveness of AI. Also the bigger the model, the more powerful hardware and infrastructure costs you will need. On the other hand, if you are an organization that has assembled a massive model, it increases the moat for others to catch up…sort of. Let’s find out why.
Context
The second method is perhaps the easiest way to improve AI effectiveness, where you can simply add context to a given prompt, such as, “How should I dress today?”
ChatGPT might not even have a good answer:

Thus, by adding to the prompt, I can get a more complete answer, let’s try, “The weather outside is hot today, and it will not rain, it is also not humid, how should I dress today?”

GPT4 gives a very comprehensive and complete answer, however it is not direct. To improve the effectiveness of the language model, it would be helpful if the context also specified a more predictable outcome, such as, “You are forced to give me a specific outfit to wear today…” before the prompt.
By giving the LLM as much context as possible, you are giving it “clues” to find the right answer based on its probabilistic outcomes. However, it could get exhausting giving as much context as possible, therefore many companies and products are front running outputs by adding as much context as possible. As an example, Google’s Bard supplements answers with real time information in the prompt to get the right results to you. It could be redirecting to its search capabilities first before showing you a result from its LLM.
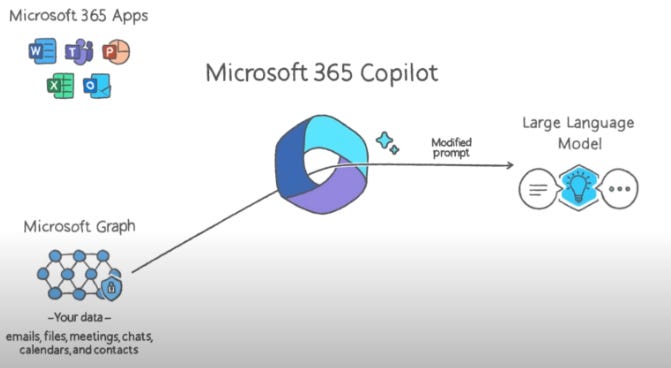
This is also how Microsoft 365 Copilot will work with your files, it will create a search graph of your entire database, and try to pass some of the points into the prompt. This in theory should give you a comprehensive reply based on the parameters, though at scale it may differ from organization to organization. It is unlikely that this will perform well when really looking for granularity, since there is only so much you can pass as context without slowing down the retrieval process..
It is also important to note, that throwing more context does not necessarily mean better outcomes. But better quality context will yield much better results. There is more complexity to this, such as adding a Vector DB to achieve more specific results to pass through the prompt, but that would then increase the cost to build and run the model too. We thus rate this (without adding complexity):
Cost to build: Low
Cost to run: Low
Effectiveness: Medium
Scaling factor: High
What about increasing context length? If I cram more information into the prompt, I can get better results right? Well, there’s definitely a limitation here, and a better method to pass massive context is Fine Tuning.
Fine Tuning
Finally, the third method to improve AI outcomes is called Fine Tuning. This adds a file or multiple files on top of both the prompt and the model that is more customized to the specific use case. It’s something I’ve been experimenting with in a few of my articles, and some that I didn’t publish because the findings varied. This is extremely effective because it is designed to improve performance without adding too much cost to running the model. It is also extremely good at scaling in organizations because you can fine tune multiple models for different use cases. In fact, there are already marketplaces that sell fine tune models for Stable Diffusion and LLMs. The catch is that there is a moderate degree of cost to build these models, and results may vary depending on the data used to train.
In order to fine tune a model, you do require a large enough amount of data to train on. This means that you are building a new model that works with the base model, but requiring the compute power to do it. Depending on how your infrastructure is set up and the method of fine tuning, it can range from minutes to hours. However this is magnitudes faster than retraining the base model. Fine tuning is also how Google’s Med-PaLM 2 is built, they took a large medical dataset and trained it with PaLM 2, however, the medical dataset was many orders of magnitude smaller than the base model.
At Codeium, we think we have a specific advantage with Fine Tuning and personalizing the dataset to work with different organizations. The advantage of having a self-hosted GPU allows us to utilize idle time to run these models for different code bases, thus allowing users to have a much better experience without harming performance or cost. If this offering was given by some other AI coding platforms (for example Copilot or Tabnine), we don’t think they would have the expertise we do to keep the costs low enough to make this scalable for larger companies.
Cost to build: Medium
Cost to run: Low
Effectiveness: High
Scaling factor: Medium
Now what if you combined these 3 methods to create the perfect output? For example training a very specific base model, providing a large amount of relevant context, and fine tuning the model even more for personalized data. This is really where the magic happens, however, it is a trilemma because in theory you could go deeper and deeper at each of the 3 points of the triangle but it gets more and more expensive. With any AI company with limited resources, they must choose how to improve their results by investing into the base model, context, or fine tuning accordingly. As you get more use case centric, these also get squeezed even more towards a purpose.
As you can see, the various methods of improving performance for LLMs each have trade offs. Where other companies have advantages, like OpenAI with model size, or Open Source with variations of Fine Tuning, or Microsoft using a search graph on its productivity products to map context, we’re still in the extremely early stages of AI performance and how much improvement there can be. There are other more detailed types of methods like RLHF and PEFT and more, and new research papers coming out everyday, so this “trilemma” is really just a simplification. This is especially true when we think about multimodal LLMs…but we’ll save these for another time. Things are only just starting to get interesting.