


A lot of people have asked what the next frontier is for AI, after all we’ve seemed to conquer text, voice, and now with Google’s last I/O, video. It’s not far out where we’ll get on the fly content or media as GPUs get more and more powerful. But let’s step aside for a moment and talk about where things are naturally progressing and that is in the realm of robotics.
With GPU compute becoming much less of a barrier to this becoming a reality, it seems that the next frontier is limited by data. After all, there isn’t petabytes of text and video to train on that will make this a reality, and training a model that robots can use must have way different parameters than something that is more deterministic. Let’s take a step back and see what actually goes into a model. First off as with any model, you need to understand what are the options and what entails a successful behavior and reward. The inputs here are mainly what the robot can see and “feel”. For what it can “see”, it has images and video data fed from camera/sensors all around it. Even this isn’t enough though, for example it may need multiple cameras or sensors to even understand depth. With enough of these parameters it can at least understand its environment or even map out and understand what objects are available for it to interact with.
Once a robot understands its environment, it then needs to understand the objects and routes in the room, this becomes really complicated to train a robot, it must figure out what options it has to accomplish a goal. For example if I’m trying to throw garbage away there’s probably hundreds of ways to do this with other tools or different methods of getting the object into the trash can (okay, maybe at this point I’m just staring at what’s in front of me). But you can imagine this being far more complex than let’s say, an agent learning what tools it has available and executing these tasks accordingly. The tools that are available to the robot are constantly changing given the environment!
We also have to worry about human interaction, is this with speech/text, or something more complex like understanding human movement and emotions? How a robot interacts with humans though has been slowly getting better with LLMs, so maybe we can just delegate that task to those models.
As you can see there’s so many variables compared to what LLMs have conquered so far, even multimodal ones. In fact, you can imagine a robot being multimodal on way more dimensions. Here are a few that really matter:

A bit harder to find data than LLM training
Just to touch base on the types of models versus LLMs, perception models focus on visual and spatial data. This type of input is very different from LLMs which focus mainly on text but lately images and audio as well. That means whatever input data robots have, it’s navigating through physical space, whereas the trajectories for LLMs are mainly sequences in text. We’ve just touched based on navigating a space just now, but there’s also how to interact with the objects too! So if you think about what that means, you’ll need to add input data from “feeling” an object, how “squishy” the object is, and how much to grasp or hold it. It’s a whole other vector to worry about. And as we’ve stated above, if you want to train a robot on this type of data, you’ll need to really expose it to many different scenarios and environments to figure out how to achieve its objective, whereas in the LLM case you’re just finding more and more text that can showcase what patterns exist in the real world. However, the good news is, there should be an outcome that is achievable, like picking up an object and placing it somewhere else, but it’s far more complex than what’s easily available on the web.
However, just because it is complex doesn’t mean it is impossible, for example Google DeepMind and Nvidia have been making the notion of a “digital twin” very useful in how to train models for robots. If you had a virtual world that was a perfect environment of matching physics and objects, you could run a crazy amount of simulations for the robot to try different modalities and outputs to see if it got things right. This was previously limited by compute but it is getting more and more possible as things scale up faster. In fact this month Nvidia just released an update, Isaac GR00T N1.5, its foundational model for robots. We’ve seen several real life deployments of robots, including the Roomba which just needs to vacuum and figure out how to navigate a simple floor, or Amazon’s robots that need to figure out how to get items to delivery as efficiently as possible. We’ve seen the dancing robots at Boston Dynamics and Tesla, but with Boston Dynamics in particular showing the combination of whole-body coordination and control, real-time perception, and reinforcement learning all in real life! However, with Tesla’s advancements and Xai’s massive GPU cluster, we may see them catch up very quickly. It almost makes sense for Tesla to acquire Xai simply to get the compute and team to work together on what the priorities should be.
In the startup realm, there are some names like Figure and Apptronik. OpenAI also invested in a company called 1X Technologies. Strangely though, the total amount going into robotics has gone down as a percent of overall VC investments:
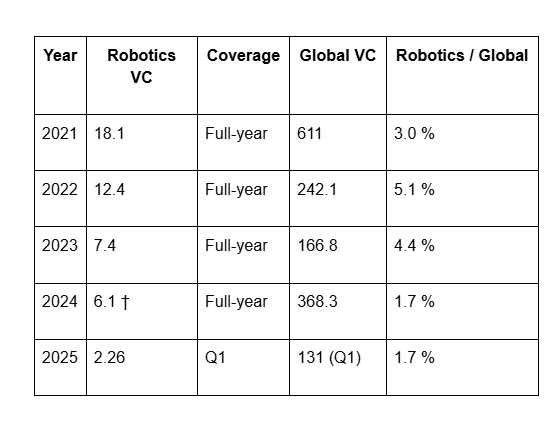
The easiest explanation here is that late stage rounds are piling into more of the foundational companies like OpenAI and Anthropic, which including Tesla, Nvidia and Google are exploring this space as well. That means that “standalone” robot companies may have a tougher time than larger companies in this arena. It’s pretty well known that any investments that are capital intensive, particularly anything with hardware or physical materials, the return gets diluted very quickly in each subsequent round. That means that investing into companies with a more diverse portfolio to gain revenue would make more sense as they can shoulder the costs as things ramp up elsewhere in the company. Google is perhaps best positioned for this, and they have proven to execute on this with Waymo and self-driving, which is really just another form of “robot”.

Going forward, the timeline for mainstream adoption looks very rapid, within the next 2-3 years, we might see robots helping out with various tasks at home. Whether it’s lifting heavy things, cooking, or cleaning up (alongside your roomba), things will happen faster than you think. It’s too bad we didn’t get babysitters sooner, I could have really used that.
If things really scale out though, the “age of abundance” dream is likely possible. It could drive down costs for not just childcare like I just mentioned, but elder care, and replace things like construction and physical labor that could be dangerous. As usual, there will be controversy of job displacement, but the reality is that society benefits from the burdens of paying the cost for these high value roles. It might also set off another AI race, the country that hits this age of abundance will be the one that moves faster on building products, building infrastructure, and so on. While exciting, we’ll have to expect some resistance, and not everybody will become a winner until there is extreme excess in the benefits.
Great post