
OpenAI o1
An LLM that can "think", but at what cost?


There was a pretty major breakthrough in the world of LLMs in September but I found it strangely quiet given how the industry usually jumps and exaggerates on these topics. How come there isn’t more excitement about this? Am I simply living under a rock? Maybe we are getting to a point where the vast majority of queries and prompts can be addressed with the latest frontier models, but it’s that remaining smaller percentage of use cases that require new paradigm shifts to impress. I can tell you though, that with GPT-o1, a bunch of those use cases just got solvable, even if it is a much smaller percent. I could go on a tangent about how o1 is a very confusing name after 4o, but you know what, I’ll save it for a tweet or something.
Now how come it took so long to arrive at this model and why is it different from others? I think so far the industry has gotten used to shipping models quickly and getting users to get an input and response. However, in general for these models, users and AI companies have a goal but also a constraint, for users:
Goal: the accuracy of the response
Constraint: the amount of time it takes to get an answer
For AI companies it’s:
Goal: how good the model is
Constraint: the cost or compute to run a model
Typically, different scenarios have different constraints, for example at Codeium the autocomplete model must fit the constraints of having very low latency and thus very quick time. For a chat model, the user is willing to wait a second or so before getting the response, and this can even be hidden by streaming tokens.
But what if there are use cases where the user was willing to increase the accuracy but okay with increasing the time? This is where OpenAI o1 comes in. By taking away the constraint of time, and potentially adding a lot of compute, OpenAI has the freedom of coming up with a new way to solve harder problems. Just for fun, I thought about what would be a hard problem for an LLM to solve, for example breaking something into tokens that could overlap, or forcing a model to analyze individual letters. A very simple example would be this prompt: how many 3 or more letter words can you make from the word “Unsolvable”. I first tried with the previous best OpenAI model, GPT-4o:
Surprisingly, when using GPT-4o, it started to try to use python to write a script so I thought it would be easy, but then it actually broke as you see above. I tried again and it tried to guess between 200 and 300.
I tried GPT4 and GPT-4o mini but those explicitly said they were unable to solve this problem. This is also why the “How many R’s are in Strawberry” usually fails the test too, if there are overlapping tokens for “Strawberry”, it may confuse itself with the meaning of individual letters.
I tried this in GPT-o1-preview, and it wrote out the strategy to solve the problem before getting pretty close:
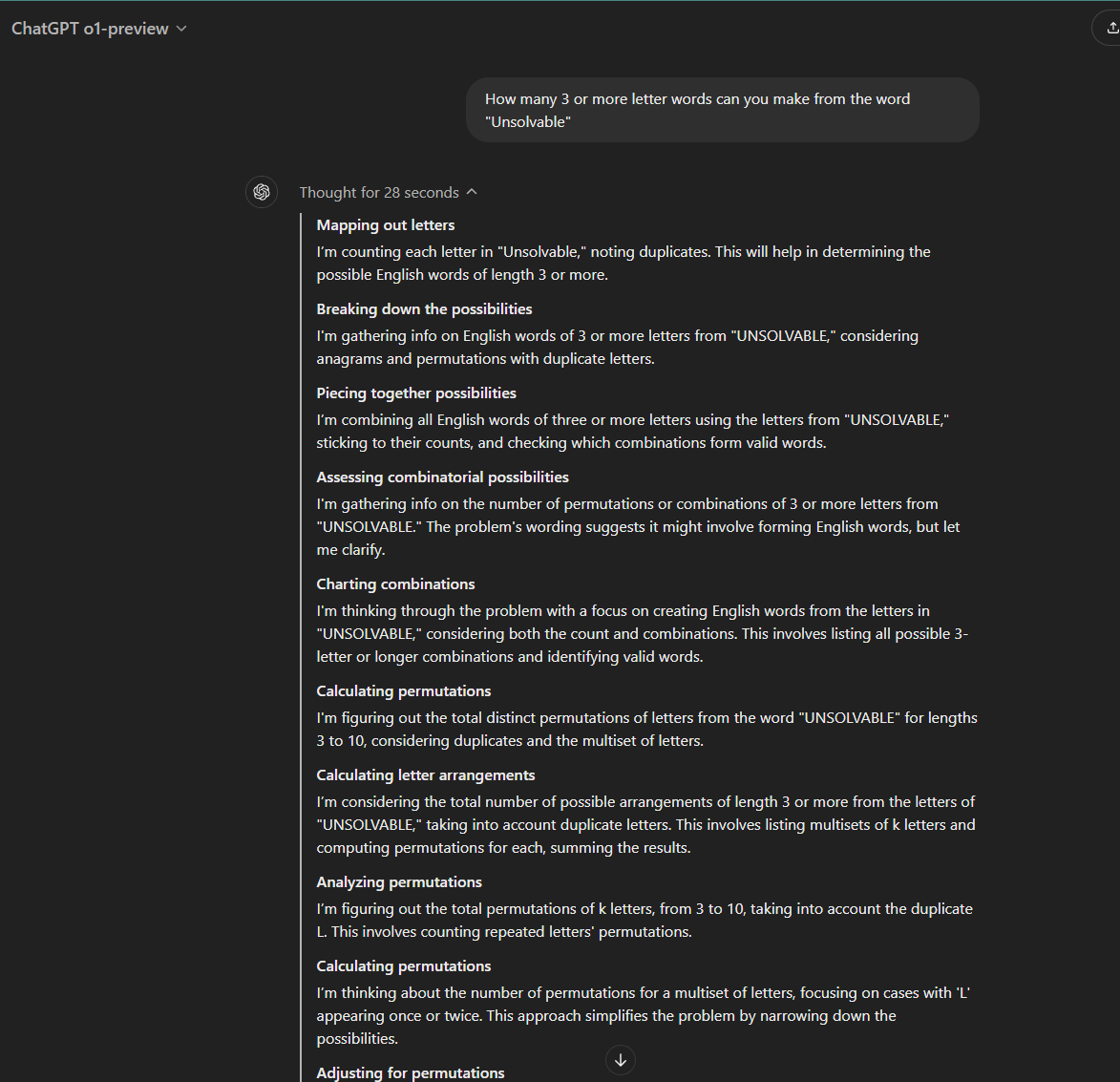
Notice this new “Thought” field popped up with o1 and took 28 seconds. This thought process is new to o1, which actually maps out how to solve the problem. It takes time because it’s building out the strategy before actually giving an answer.
According to some unscrambling websites, the answer is 439 or 455, o1 said it was 436. It’s not saying o1 is wrong since there may be definitions that might not add up, but it’s way more accurate and close. I also want to add, GPT-o1-mini could also not solve this problem with logic, it took 10 seconds instead of 28, but guessed between 70-80.
Okay, I think we’ve proven a bit that this is a puzzle that’s specifically hard for LLMs and that that o1 is pretty good, but what are the actual stats? Well according to OpenAI, the gap between certain benchmarks are pretty insane:
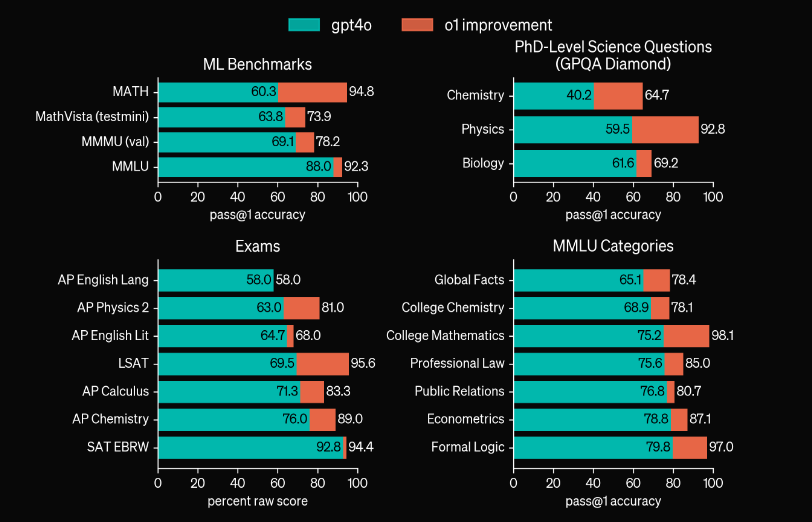
As you can see the Math and Physics benchmarks have blown the previous numbers out of the water, but it’s made advancements on coding as well, jumping from 11%ile to 89%ile on the Codeforces competition.
You’ll notice on their research post, they are hiding data on what separates this model from others, and that’s Chain of Thought (CoT). You’ll notice there’s a “competition sandwich” in their quote: “Therefore, after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users.”
That being said, with CoT, OpenAI has really made a breakthrough here, it appears they’ve trained a model based on logic and reasoning, and to do backtracking to make sure it can give better answers. A typical LLM will only move forwards and if it gets one token wrong it can ruin the rest of the response, but this Chain of Thought mechanism deliberately tries to find paths where it can correct its course even while streaming the data back to the user. This is likely hidden though in the “thought” process while you wait.
Just to give a hint about how this could work, former OpenAI Chief Scientist Ilya Sutskever was part of a paper called “Let’s Verify Step by Step” which details how you could actually do reinforcement learning on step by step strategies for different problems: https://arxiv.org/pdf/2305.20050
This is probably how o1 is trained, it tries different strategies and sees how far it can get with each path, but it also means that o1 is still limited to the strategies humanity has presented in front of it, rather than thinking of new strategies for new situations. That means it may not be considered AGI, and that it’s only good at things people have documented on how to solve. Still, that’s a pretty large number of problems the rest of the world probably could use.
Back on the technology side, this probably also means they are using a lot of parallel inferences behind the scenes, and to hint at why I think this, they are still capping the usage of o1-preview to 50 queries per week, are you telling me I can only solve my puzzles 7 times a day? The other hint is of course how much it costs to use o1, which is 4x more than GPT-4o. Even if you were to guess how much compute it takes to run o1, 4x is probably at least in the range, but I would guess it’s probably way more since they would likely want as many people to try it out as possible.
So in summary, for certain use cases, the user is probably willing to allow less constraints. In this model, the biggest constraint we’ve “allowed” is adding time. When you need help for a harder problem and are making an inference, GPT-o1 spends more time trying to figure out the right answer based off of strategies it’s been trained off of, which is unlike how other LLMs work. You put something in, you get something back based on the size of the model and the compute. Here you put something in and it “thinks”. The whole concept of “thinking” just came to LLMs, which is just one more step towards AGI. Now, as a human, think about the future, as compute becomes more powerful and these models become more efficient, time will only be another bump in the road.