


Llama 3.1 405B
Open source has caught up to closed source


It’s a historic week, Llama 3.1 405B has come out and it’s fabulous. It’s the day that open source “caught up” to closed source. It means that in theory any company can deploy and run a frontier model either for internal or external use.
There’s quite a bit to cover here and I’ll simplify as much as possible. First let’s cover how 405B compares to other models, then some of how it was built, then we can dive into the possibilities.
Without going to much into detail on this benchmark sheet, 405B beats even the best models in many of the categories. It seems the only metric that it is actually behind on is the GPQA reasoning metric (448 questions on science domains) from Claude 3.5 Sonnet, but overall it could literally just be better than GPT-4. Let than sink in…it’s also not really mentioned much but even Llama 3.1 70B is also pretty toe to toe with GPT-4 as well on the benchmarks.

Now, looking past these benchmarks, GPT-4 omni still has some advantages, one is that it’s multi-modal (it can take in audio and image/video), it’s likely faster (due to the latency improvements), and its new “mini” version is far cheaper and obviously timed in conjunction to be competitive with providers offering 405B. Now OpenAI and Anthropic could potentially go head to head with these providers as an API service to frontier models.
Just to give some costs for 1M input output tokens on frontier models:
GPT-4o is $5/15
GPT-4o mini is $0.15/0.6 (wow)
Claude 3.5 Sonnet is $3/15
Clause 3 Opus is $15/75 (wow in the opposite direction)
And brand new is Mistral Large 2, which is $3/9
So how much would companies charge for Llama 3.1 405B? As an example, Databricks will charge $10/30, putting it squarely above GPT-4o but not quite Opus levels. It’s actually a surprise they are putting it so far ahead of Claude 3.5 Sonnet, but there are some reason which we’ll get to later.
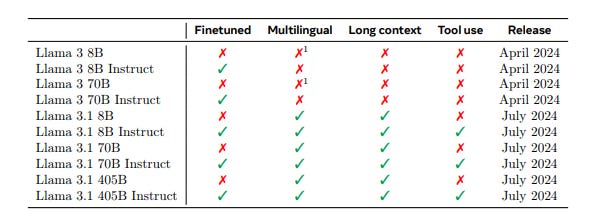
In terms of other things to know, Llama will be called a “herd” of models, and include all the other variants of 8B, 70B, and 405B base and instruct models. Also worth noting, it’s now Llama 3.1 instead of 3, meaning the new version has multi-lingual and long context support. In fact, the 405B model has a whopping 128k context window, which of course does bring some limitations while hosting this yourself.
From a licensing perspective, you can run this model for any business and make money on it. Even Mistral Large 2 is non-commercially available, which was a strategic decision but makes it hard to compete against Llama. Even though it’s a ~100B size model, it is in between the 70B and 405B models that are commercially viable. Llama 3.1 even lets people generate synthetic data and distill models, or using it to train your own models. This is an unbelievable amount of value just given away for free, so why is Mark Zuckerberg doing this?
While he says that openness can make sure power isn’t concentrated and that sounds all rosy and friendly, the longer term strategic reason is setting the industry standard. Wherever Meta goes with these models, all future models will utilize their stack of tools and standards, and there will be a worldwide ecosystem of infrastructure and applications that will always support it. Having a strong ecosystem is way more valuable to Meta especially when the depreciation of these models is so fast. In the world of LLMs if you are on top it’s only a few H100 hours away from being behind. If you have an ecosystem though, you are always ahead, and just like PyTorch and React, Meta will be able to have the community accelerate on the innovation. This does not come cheap.
To train this model, Meta used 16k H100s trained on 15T tokens, which even pegged at $30k each ends up being nearly half a billion dollars just to buy the hardware. Obviously they will still have some juice left to train Llama 4 (which is rumored to be multi-modal and possibly a mixture of experts), which started training last month. This makes Elon’s xAI Memphis cluster pretty massive, with 100k H100s. These numbers are actually hard to wrap your head around, don’t even get me started on how much electricity this is taking.
So what are the implications here. First off, it’s not cheap to run this model, you’ll need an 8xH100 configuration (running on fp8 roughly maps to the amount of VRAM needed, and 8xH100 can support 640GB to match the 405B and leave some room for the wide context). To buy one of these boxes, you’ll need around $250-300k. That’s actually a lot of OpenAI API credits…so is it actually worth hosting it yourself? If a company is really serious about hosting this model, you’d need to run about 33B of tokens on GPT-4o or 700B tokens on GPT-4o mini to break even, not to mention the extra maintenance cost. Maybe it’s still worth it but remember you are limited now by throughput which surprisingly cannot serve 100s of users at once easily. If you’re thinking of running a service for thousands of concurrent users…probably consider the costs unless you want to have a lot of 8xH100 nodes lying around.
Every existing stack will probably need to be upgraded to serve or modify this model. This is great news for Nvidia and hardware providers, there will be a lot more purchase orders coming for inference due to this model. The world has now added a reason to purchase more inference servers and in turn more companies will also be willing to buy training clusters to modify this model. In fact, a year from now, an 8xH100 may seem like a toy and necessity for every organization. I know it sounds crazy but last year we thought an 8xA100 was a monster machine, and now it’s weird that it’s so many generations behind. Strangely enough, AMD might be an interesting thing to monitor if their 192GB MI300X can actually run large batch sizes in the 4x configuration, they have been strangely quiet on scaling large 405B deployments though, but this is there chance to enter the arena.
The game has really changed, now it’s not just OpenAI and Anthropic taking all the market share, now any company can serve a frontier model (at a cost) to compete. Even the existing training clusters that might go obsolete next year when GB200s are more available might start considering operating an API service to serve 405B instead of filling capacity, but they need to consider that this could also be a race to the bottom. In fact, the number of services offering this is already massive:

Trying to be a 405B provider is going to be extremely competitive, but early signs are these services are not undercutting each other (yet). If you’re a company trying to break into AI, the app layer should be where you compete, not the model layer.
OpenAI has been dealt a severe blow this week, even on top of today’s news that it may run out of cash as soon as 12 months from now. To me this is overblown since they have some serious powerhouse technology yet to be announced, however their lead may not be as obvious now. I would not underestimate them, but I would also say, the playing field has evened.